16 逆向索引:缩小搜索范围(第2/2页)
Frank打断了他:“关于这个线头,你还能告诉我什么其他的信息吗?”
店主看着他说:“一件被施了咒语的新的警察披风,除此之外……”
Frank等待着。
“额……没了,”Cloaksworth最终说道,“全都说完了。”
Frank点了点头说道:“谢谢!”他拿起那根线头,转身准备离开。在他走出门的时候,他听到店主倒吸了一口气,Frank想,店主肯定看到他披风尾部那被磨烂的边缘了。
警用算法导论:逆向索引
节选自Drecker教授讲义
逆向索引是计算中要用的一种数据结构,它和书的索引类似。对于每一个值,逆向索引可以告诉你这个值在数据中的哪些地方出现过。如果一个值会在数据中反复出现,这一点就格外有用。
想想我们在讲二分搜索的时候用到的一个例子——在一个账本中查找和一个特定商人进行的所有交易记录。账本上的记录是按交易编号从小到大排的,也就是按交易时间从早到晚排序的。
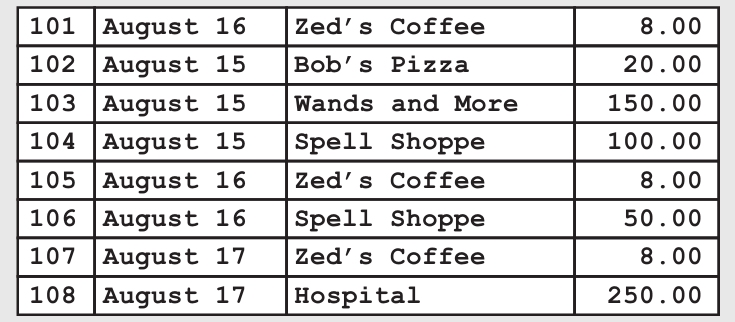
在知道交易编号的情况下,这种排序可以让我们很快找到交易记录,但它并不能帮助我们找到与某个特定商人进行的所有交易。当然,我们可以按照商人的名字重新排序。但这样做的工作量很大,因为这意味着我们需要重新做一本账本。
我们可以建立一个额外的数据结构:一个以商人名字作为关键词的逆向索引。对于每一个商人,我们可以在索引中存下所有相关交易的编号。因为我们已经可以从编号很容易地找到交易记录,所以这个额外的索引就可以让我们很容易地找到与某个特定商人相关的所有交易记录了。
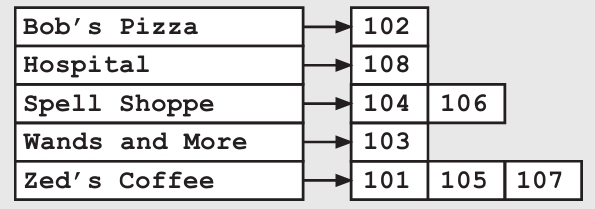
逆向索引是一个很典型的需要在运行时间和内存占用两者之间取舍的例子。添加一个逆向索引会占掉更多的内存,但它也让我们在一个新的维度上进行搜索的效率得到了极大提升。